
Дерево Хаффмана — это эффективный алгоритм сжатия данных, который основан на идеи замены более длинных кодов более короткими. Дерево Хаффмана позволяет определить, какие символы встречаются чаще, и присвоить им более короткие коды, а символам, которые встречаются реже — более длинные коды.
Создание дерева Хаффмана начинается с определения частоты встречаемости каждого символа в тексте или наборе данных, который нужно сжать. Далее, символы сортируются по возрастанию их частоты. Затем два символа с наименьшей частотой объединяются в новый узел дерева, у которого частота равна сумме их частот.
Этот процесс повторяется до тех пор, пока все символы не будут объединены в одном дереве Хаффмана. В итоге, более часто встречаемые символы будут иметь более короткие коды, а редко используемые символы — более длинные коды. Таким образом, текст или данные могут быть сжаты и переданы более компактно.

Определение дерева Хаффмана
Дерево Хаффмана – это особая структура данных, используемая для эффективного сжатия информации. Оно названо в честь американского ученого Дэвида Хаффмана, который разработал алгоритм его построения в 1952 году.
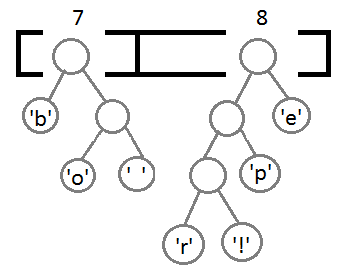
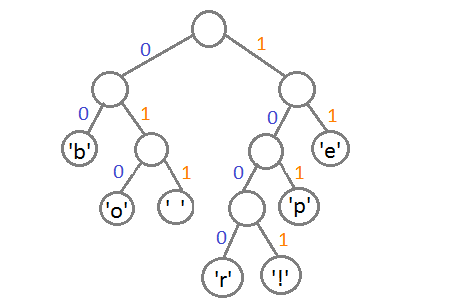
Дерево Хаффмана представляет собой двоичное дерево, в котором каждая внутренняя вершина имеет двух потомков (левого и правого), а листья соответствуют символам, которые нужно закодировать. Каждое ветвление в дереве Хаффмана определяет один бит кода: направление ветвления влево – это 0, а направление ветвления вправо – это 1.
Строительство дерева Хаффмана основывается на частоте встречаемости символов в исходном тексте. Чем чаще символ встречается, тем короче его код в дереве Хаффмана. Таким образом, наиболее часто встречаемым символам присваиваются наиболее короткие коды, что позволяет достичь эффективного сжатия информации.
Преимущества дерева Хаффмана состоят в его способности обеспечить высокую степень сжатия для различных типов данных, включая текстовые, звуковые и изображения. При этом, восстановление исходной информации из сжатых данных происходит без потерь, что делает дерево Хаффмана очень полезным инструментом в сфере коммуникаций и хранения данных.
Эффективность использования памяти является еще одним преимуществом дерева Хаффмана. Благодаря коротким кодам, занимающим минимальное количество бит, размер сжатых данных значительно уменьшается по сравнению с исходными данными. Это особенно важно при работе с большими объемами данных или при передаче информации по сети с ограниченной пропускной способностью.
Дерево Хаффмана находит широкое применение в различных областях, где требуется сжатие информации. Оно используется в сетевых протоколах, архиваторах, аудио и видео кодеках, а также в системах хранения и передачи данных. Благодаря своей эффективности и простоте реализации, дерево Хаффмана является одним из основных методов сжатия данных.
Однако, использование дерева Хаффмана имеет свои ограничения и сложности. Например, для кодирования и декодирования информации требуется предварительное построение дерева Хаффмана, что может занимать значительное время и требовать больших вычислительных ресурсов. Кроме того, в случае изменения исходных данных, дерево Хаффмана может потребоваться перестроить или модифицировать, что может быть сложно в реальных условиях использования.
Коды Хаффмана Алгоритм построения дерева
Принцип работы
Дерево Хаффмана является универсальным инструментом сжатия данных, используемым во многих областях, включая компьютерную науку и телекоммуникации. Основной принцип его работы заключается в том, что более часто встречающиеся символы кодируются более короткими битовыми последовательностями, а реже встречающиеся символы — более длинными.
Для построения дерева Хаффмана сначала необходимо проанализировать исходный набор данных и подсчитать частоту встречаемости каждого символа. Затем символы сортируются по частоте, образуя первоначальные листья дерева. Далее происходит объединение двух наименее часто встречающихся символов в один узел, суммируя их частоты. Новый узел становится родителем для объединяемых символов, а его частота равна сумме частот объединяемых символов. Этот процесс повторяется до тех пор, пока все символы не объединятся в одном корневом узле, который становится головой дерева.
Каждому символу присваивается код на основе пути от корня к листу, где находится данный символ. При этом левому потомку соответствует бит "0", а правому — бит "1". Таким образом, кодирование и декодирование информации происходит по пути от корня дерева к соответствующему символу.
Преимущества дерева Хаффмана заключаются в его эффективности сжатия данных и возможности однозначного декодирования информации. Этот метод широко используется в сжатии аудио-, видео- и изображений, а также в алгоритмах сжатия файлов.
Однако дерево Хаффмана имеет свои ограничения и сложности. Одна из сложностей — это необходимость хранения таблицы с кодами для каждого символа, что может стать проблемой при обработке больших объемов данных. Также алгоритм сжатия работает эффективно только при достаточно большой пропорции повторяющихся символов в исходном наборе данных.
Строительство дерева Хаффмана
Дерево Хаффмана строится путем объединения двух наименьших частотных узлов (символов или поддеревьев) в новый узел, который становится родительским для этих двух узлов. При этом сумма частот потомков равна частоте родительского узла.
Процесс построения дерева Хаффмана начинается с создания листьев для каждого символа и присвоения им соответствующей частоты, которая определяет их важность в итоговой кодировке. Затем создается приоритетная очередь, в которую помещаются все листья. Листья с наименьшей частотой имеют наибольший приоритет.
Далее происходит цикл объединения узлов:
Шаг 1:
Извлекается из очереди узел с наименьшей частотой и становится левым потомком нового узла.
Шаг 2:
Извлекается из очереди узел с следующей наименьшей частотой и становится правым потомком нового узла.
Шаг 3:
Вычисляется сумма частот двух потомков. Создается новый узел с этой суммой частот и становится родителем для двух потомков.
Полученный новый узел возвращается в очередь с приоритетом, занимая место, соответствующее его суммарной частоте. Цикл объединения узлов продолжается до тех пор, пока в очереди не останется только один узел — корень дерева Хаффмана.
Построенное дерево Хаффмана характеризуется тем, что более часто встречающиеся символы имеют более короткие коды, а менее часто встречающиеся символы имеют более длинные коды.
Преимущества дерева Хаффмана
Дерево Хаффмана — это эффективная структура данных, которая используется для эффективного сжатия информации. Оно представляет собой двоичное дерево, в котором каждая внутренняя вершина имеет двух детей, а листья содержат символы и частоты их повторений. Преимущества дерева Хаффмана делают его одним из наиболее популярных методов сжатия данных.
Основными преимуществами дерева Хаффмана являются:
| Потери информации: | Дерево Хаффмана не приводит к потере информации при сжатии. Все данные точно восстанавливаются при распаковке. Это отличает его от других методов сжатия, где возможна потеря информации. |
| Эффективность: | Дерево Хаффмана позволяет достичь высокой степени сжатия данных. Оно оптимально кодирует символы с наибольшей частотой повторений, что позволяет сократить количество битов, необходимых для их представления. |
| Быстродействие: | Дерево Хаффмана позволяет быстро сжимать и распаковывать данные. Построение дерева и кодирование информации происходят за линейное время, что делает его очень эффективным для больших объемов данных. |
| Универсальность: | Дерево Хаффмана применимо к любому типу данных. Оно не зависит от контекста и может быть использовано для сжатия текстовых файлов, изображений, аудио и видео данных. |
Преимущества дерева Хаффмана делают его неотъемлемой частью современных методов сжатия данных. Он широко применяется в программных приложениях, операционных системах, сетевых технологиях и телекоммуникационных системах для сжатия, хранения и передачи информации с оптимальным соотношением размера файла и качества восстановления данных.
Эффективность использования памяти
Дерево Хаффмана является особенно эффективным в использовании памяти, поскольку оно позволяет эффективно сжимать информацию, уменьшая объем занимаемого места. Это особенно важно для передачи данных, хранения больших объемов информации и работы с ограниченными ресурсами.
Основная идея дерева Хаффмана заключается в том, чтобы более часто встречающимся символам присвоить более короткий код, а символам, встречающимся реже, — более длинный код. Таким образом, часто используемые символы занимают меньше места в памяти, что позволяет сократить общий объем хранимой информации.
Кроме того, дерево Хаффмана позволяет сохранить информацию о частоте встречаемости символов в самом дереве. Это позволяет с легкостью восстановить исходную информацию и выполнить обратное преобразование. Благодаря этому, сжатие информации с использованием дерева Хаффмана является потерьным.
Преимущества дерева Хаффмана в использовании памяти:
— Экономия объема памяти за счет сжатия информации;
— Возможность работы с ограниченными ресурсами;
— Быстрое и эффективное восстановление исходной информации.
В результате использования дерева Хаффмана, объем памяти, необходимый для хранения информации, сокращается, а производительность и эффективность работы увеличиваются. Поэтому данная структура данных широко применяется в областях, где важна экономия ресурсов памяти, таких как сжатие данных, архивация, сетевые протоколы и другие.
Применение дерева Хаффмана
Дерево Хаффмана является одним из основных алгоритмов сжатия данных и находит широкое применение в различных областях.
Основным применением дерева Хаффмана является сжатие данных. Алгоритм Хаффмана позволяет эффективно упаковать информацию, удаляя избыточные символы и используя минимальное количество битов для представления данных. Это особенно полезно при передаче информации по сети или хранении больших объемов данных.
Кроме сжатия данных, дерево Хаффмана также используется для построения оптимальных кодов. Оптимальные коды помогают ускорить поиск и обработку информации, так как каждому символу присваивается уникальный код, который занимает минимальное количество битов. Это особенно важно в задачах поиска и сортировки больших объемов данных, где каждая операция должна быть выполнена максимально быстро.
Дерево Хаффмана также может использоваться для сжатия изображений и звуковых файлов. Алгоритм Хаффмана позволяет удалить избыточные данные, сохраняя при этом качество изображения или звука. Это особенно важно при передаче и хранении больших файлов, так как позволяет сократить объем информации без существенных потерь в качестве.
Кроме того, дерево Хаффмана используется в компьютерной графике для сжатия текстурных данных. Сжатие текстур позволяет уменьшить их размер, что положительно сказывается на производительности графического процессора и скорости отрисовки объектов.
| Область применения | Примеры |
|---|---|
| Сжатие данных | Сжатие текстовых файлов, сжатие аудио и видео данных |
| Построение оптимальных кодов | Поиск и сортировка данных |
| Сжатие изображений и звуковых файлов | Сжатие JPEG и MP3 файлов |
| Сжатие текстурных данных | Сжатие текстур в компьютерной графике |
Таким образом, дерево Хаффмана является мощным инструментом для сжатия данных и построения оптимальных кодов. Его применение охватывает различные области, от передачи данных по сети до обработки графических объектов. Благодаря своей эффективности и простоте реализации, дерево Хаффмана продолжает оставаться одним из основных алгоритмов в области сжатия и кодирования информации.
Кодирование информации
Кодирование информации является одним из основных применений дерева Хаффмана. Оно позволяет сжимать данные без потери информации.
В процессе кодирования информации каждому символу или комбинации символов присваивается уникальный двоичный код. Это позволяет представить данные в виде последовательности символов из множества {0, 1}. Кодирование основано на принципе, что наиболее часто встречающиеся символы получают более короткую последовательность битов, а реже встречающиеся символы получают более длинную последовательность битов.
Процесс кодирования информации с использованием дерева Хаффмана может быть представлен в следующем виде:
- Анализ исходного текста или данных для определения частоты появления каждого символа.
- Построение дерева Хаффмана на основе частоты появления символов.
- Присвоение двоичных кодов каждому символу на основе пути от корня дерева до соответствующего листа.
- Кодирование информации с использованием полученных двоичных кодов.
Дерево Хаффмана позволяет эффективно сжимать информацию и уменьшать размер данных. За счет использования более коротких кодов для часто встречающихся символов, можно достичь значительной экономии места при хранении и передаче данных.
Однако при использовании дерева Хаффмана возможны некоторые ограничения и сложности. Например, для определения кодов символов необходимо предварительно проанализировать весь набор данных. Кроме того, при декодировании данных может возникнуть неоднозначность, если некоторые двоичные коды представляют собой префиксы других кодов.
Тем не менее, дерево Хаффмана является мощным инструментом для сжатия и кодирования информации. Оно широко применяется в различных областях, включая сжатие аудио и видеоданных, хранение и передачу текстовых файлов, сетевые протоколы и многое другое.
бакалавриат_РЭТ_осенний семестр_ТЭС(рус.яз)_Практ.раб.№4. Алгоритм сжатия данных.Код Хаффмана
Сложности и ограничения
Использование дерева Хаффмана влечет за собой определенные сложности и ограничения, которые необходимо учитывать при реализации и применении данной структуры данных.
Одной из основных сложностей является необходимость построения дерева Хаффмана для каждого набора данных. Каждый раз требуется проводить процесс создания дерева, что занимает время и затраты ресурсов. Это особенно актуально при обработке больших объемов информации.
Кроме того, структура дерева Хаффмана не позволяет эффективно выполнять операции вставки или удаления элементов из уже построенного дерева. Для каждой операции необходимо перестраивать всю структуру, что может быть затратным с точки зрения производительности.
Также следует отметить, что дерево Хаффмана применяется в основном для сжатия текстовой информации или других данных с четким определением весов элементов. В случае, когда имеется большое количество элементов с одинаковыми частотами, дерево Хаффмана может использовать больше памяти по сравнению с другими алгоритмами сжатия.
Таким образом, при использовании дерева Хаффмана следует учитывать его особенности и ограничения, чтобы выбрать оптимальный подход для конкретной задачи и набора данных.



