
Построение дерева решений является одним из ключевых алгоритмов машинного обучения, который применяется во многих областях, включая медицину, экономику, биологию и многие другие. Однако, для того чтобы дерево решений было эффективным инструментом прогнозирования, необходимо правильно оценить целевую переменную.
Целевая переменная представляет собой величину, которую необходимо предсказать. Например, в задаче классификации, целевая переменная может принимать значения "да" или "нет", а в задаче регрессии, она может быть числовым значением. Оценка целевой переменной является важным этапом построения дерева решений, так как от нее зависит качество прогнозов, которые будет делать дерево.
Для оценки целевой переменной можно использовать различные методы. Например, можно применить статистические методы и анализировать распределение целевой переменной, чтобы определить ее характеристики. Также можно использовать методы машинного обучения, такие как линейная регрессия или метод опорных векторов, чтобы построить модель, которая будет предсказывать значение целевой переменной на основе имеющихся данных.
Насколько важно оценить целевую переменную перед построением дерева решений?
Процесс построения дерева решений является одним из ключевых методов машинного обучения, который позволяет классифицировать данные и делать прогнозы на основе имеющихся признаков. Однако, чтобы получить качественные и достоверные результаты, необходимо предварительно оценить целевую переменную.
Оценка целевой переменной перед построением дерева решений имеет решающее значение, поскольку от этого зависит качество модели и точность предсказаний. Значение целевой переменной определяет, какую информацию нужно учесть при построении дерева и каково будет его дальнейшее использование. Если целевая переменная неправильно оценена или вовсе не учтена, то модель может быть неэффективной и давать неверные результаты.
Почему важно оценить целевую переменную?
Оценка целевой переменной перед построением дерева решений позволяет определить, какие признаки влияют на конечный результат и какую роль они играют в принятии решений. Корректная оценка целевой переменной позволяет учесть все важные аспекты проблемы, что в свою очередь повышает точность модели.
Без правильной оценки целевой переменной мы можем упустить важную информацию или учесть ненужные признаки, что приведет к неправильным выводам и низкому качеству модели. Например, если целевая переменная — предсказание о наличии или отсутствии заболевания, но она оценена неправильно, то модель может не учесть важные симптомы и не дать точного прогноза.
Влияние оценки целевой переменной на качество обучения
Оценка целевой переменной также влияет на качество обучения модели. Если мы недооценим или переоценим ее значимость, то можем получить неправильную модель, которая будет слишком гибкой или же слишком жесткой. В первом случае модель будет иметь высокую ошибку на тренировочных данных и низкую на тестовых, так называемое переобучение. Во втором случае модель будет плохо предсказывать значения целевой переменной, не учитывая ее важность.
Таким образом, оценка целевой переменной перед построением дерева решений является неотъемлемой частью этого процесса и играет ключевую роль в формировании качественной и надежной модели. Необходимо учесть все аспекты проблемы, чтобы модель могла давать точные прогнозы и быть эффективной в решении задач.
7. Классические алгоритмы. Деревья решений.
Понимание сути анализируемой проблемы
Одним из ключевых шагов при построении дерева решений является понимание сути анализируемой проблемы. Как говорится, "чтобы решить проблему, нужно понять ее суть". Именно поэтому важно провести тщательный анализ и изучение темы или области, с которой мы работаем.
Анализируемая проблема может быть связана с прогнозированием продаж, классификацией клиентов, определением причин оттока пользователей и т.д. Все эти задачи требуют глубокого понимания бизнес-процессов и особенностей отрасли.
Понимание сути анализируемой проблемы помогает нам правильно сформулировать цель и задачи проекта. Например, если мы решаем задачу прогнозирования продаж, то целью может быть оптимизация подхода к маркетинговым активностям и повышение эффективности рекламных кампаний. А задачи могут включать исследование социально-демографических данных, анализ поведенческих паттернов и поиск корреляции между признаками.
Кроме того, понимание проблемы позволяет нам выбрать соответствующие методы и алгоритмы для решения задачи. Например, в задачах классификации может быть использовано дерево решений, логистическая регрессия, метод опорных векторов и другие. Каждый из них имеет свои особенности и применимость в зависимости от конкретной проблемы.
Кроме того, понимание сути проблемы позволяет нам обнаруживать скрытые взаимосвязи и зависимости между признаками. Например, при исследовании оттока клиентов мы можем обнаружить, что наибольшее влияние на отток оказывает неудовлетворенность клиента качеством обслуживания. Это позволяет нам принять соответствующие меры, направленные на улучшение качества обслуживания и удержание клиентов.
Таким образом, понимание сути анализируемой проблемы является неотъемлемой частью построения дерева решений. Оно помогает нам сформулировать цель и задачи проекта, выбрать соответствующие методы и алгоритмы, а также обнаружить взаимосвязи между признаками. Без этого понимания мы рискуем построить модель, которая не будет эффективно решать поставленную задачу.
Качество обучения модели
Одним из ключевых аспектов при построении дерева решений является оценка качества обучения модели. Качество обучения определяется способностью модели правильно классифицировать или предсказывать значения целевой переменной на основе имеющихся данных.
Значение качества обучения модели
Важно понимать, что качество обучения модели непосредственно влияет на ее способность прогнозировать и принимать верные решения. Правильно обученная модель может предоставить точные прогнозы и быть полезным инструментом для принятия решений в различных областях, таких как медицина, финансы, маркетинг и другие.
Метрики для оценки качества
Для оценки качества обучения модели можно использовать различные метрики, такие как точность (accuracy), полноту (recall), F-меру (F1-score) и др. Метрики позволяют оценить, насколько хорошо модель классифицирует данные и насколько близки ее прогнозы к фактическим значениям.
Однако важно учитывать, что выбор метрик зависит от конкретной задачи и особенностей данных. Например, в задаче классификации можно оценить точность модели (доля правильно классифицированных объектов), а в задаче регрессии — среднюю абсолютную ошибку или среднеквадратическую ошибку.
Оптимизация качества обучения
Оптимизация качества обучения модели достигается путем выбора оптимальных параметров модели, таких как глубина дерева, критерий разделения, минимальное количество объектов в листе и т.д. Также важным аспектом является правильная предобработка данных, включая отбор и обработку признаков, балансировку классов, устранение выбросов и т.д.
Оценка качества обучения модели также требует использования кросс-валидации, которая позволяет оценить стабильность и надежность модели на различных подвыборках данных.
В итоге, качество обучения модели является одним из главных факторов успеха при построении дерева решений. Хорошо обученная модель обладает высокой точностью и предсказательной способностью, что делает ее надежным инструментом для решения реальных проблем и задач.
Разработка правильных критериев разделения
Одним из ключевых этапов при построении дерева решений является разработка правильных критериев разделения. Критерий разделения определяет способ, по которому выбирается оптимальное разделение на каждом узле дерева.
Правильный выбор критерия разделения играет важную роль в формировании оптимальной модели, способной достичь высокой точности предсказаний. Выбранный критерий должен учитывать особенности исследуемых данных, а также поставленную задачу.
Информационный прирост
Один из наиболее распространенных критериев разделения — информационный прирост. Он основан на понятии энтропии и позволяет измерить степень неопределенности в данных.
Энтропия является мерой разброса значений целевой переменной в узле дерева. Чем больше разброс, тем выше энтропия, что означает большую степень неопределенности. Информационный прирост позволяет оценить значимость разделения и выбрать оптимальное разбиение данных на следующем уровне дерева.
Критерий Джини
Другим популярным критерием разделения является критерий Джини. Он также измеряет степень неопределенности в данных, но использует немного другой подход. Критерий Джини оценивает вероятность того, что два случайно выбранных объекта из одного узла будут относиться к разным классам.
Выбор критерия разделения зависит от конкретной задачи и свойств исследуемых данных. Некоторые критерии могут быть более подходящими для определенных типов задач, например, категориальных или числовых данных. Важно провести анализ данных и оценить их особенности перед выбором критерия разделения.
Разработка правильных критериев разделения является важным шагом в построении дерева решений. От выбора критерия зависит качество модели и ее способность предсказывать результаты с высокой точностью. Необходимо тщательно анализировать данные и выбирать критерий, наилучшим образом отражающий особенности исследуемых данных и поставленную задачу.
Прогнозирование результатов наиболее точно
Одной из важнейших задач при построении дерева решений является прогнозирование результатов наиболее точно. Целью любой модели машинного обучения является достижение максимальной точности предсказаний. Точность прогнозирования может быть измерена различными метриками, такими как точность, полнота, F-мера и другие.
Для достижения наиболее точных результатов прогнозирования необходимо правильно выбрать алгоритм обучения модели и настроить его параметры. Кроме того, необходимо учесть особенности данных, на которых модель будет обучаться, а также особенности задачи, которую необходимо решить.
В контексте дерева решений прогнозирование результатов наиболее точно осуществляется путем разделения выборки на подмножества внутри каждого узла дерева. Оптимальное разделение выборки достигается путем выбора критериев разделения, таких как информационный выигрыш или коэффициент Джини.
Выбор правильных критериев разделения является важным шагом в построении дерева решений. Правильные критерии позволяют наиболее эффективно разделить выборку на подмножества и прогнозировать результаты. Важно учитывать не только уровень информативности критерия, но и его интерпретируемость.
Кроме выбора критериев разделения, для достижения наиболее точных результатов прогнозирования необходимо обратить внимание на регуляризацию модели. Регуляризация позволяет предотвратить переобучение модели и повысить ее обобщающую способность.
Прогнозирование результатов наиболее точно также требует тщательной настройки параметров модели. Например, в случае дерева решений необходимо определить глубину дерева или минимальное количество объектов в листе. Эти параметры могут существенно влиять на точность прогнозирования.
Интерпретация результатов также играет важную роль при прогнозировании результатов наиболее точно. Важно понимать, какие признаки оказывают наибольшее влияние на целевую переменную и как они взаимосвязаны между собой. Это позволяет лучше понять сути анализируемой проблемы и улучшить точность прогнозирования.
Прогнозирование результатов наиболее точно является одним из основных задач при построении дерева решений. Для достижения этой цели необходимо выбрать правильные критерии разделения, провести регуляризацию модели, настроить ее параметры и интерпретировать результаты. Только таким образом можно достичь максимальной точности предсказаний и построить наиболее эффективную модель машинного обучения.
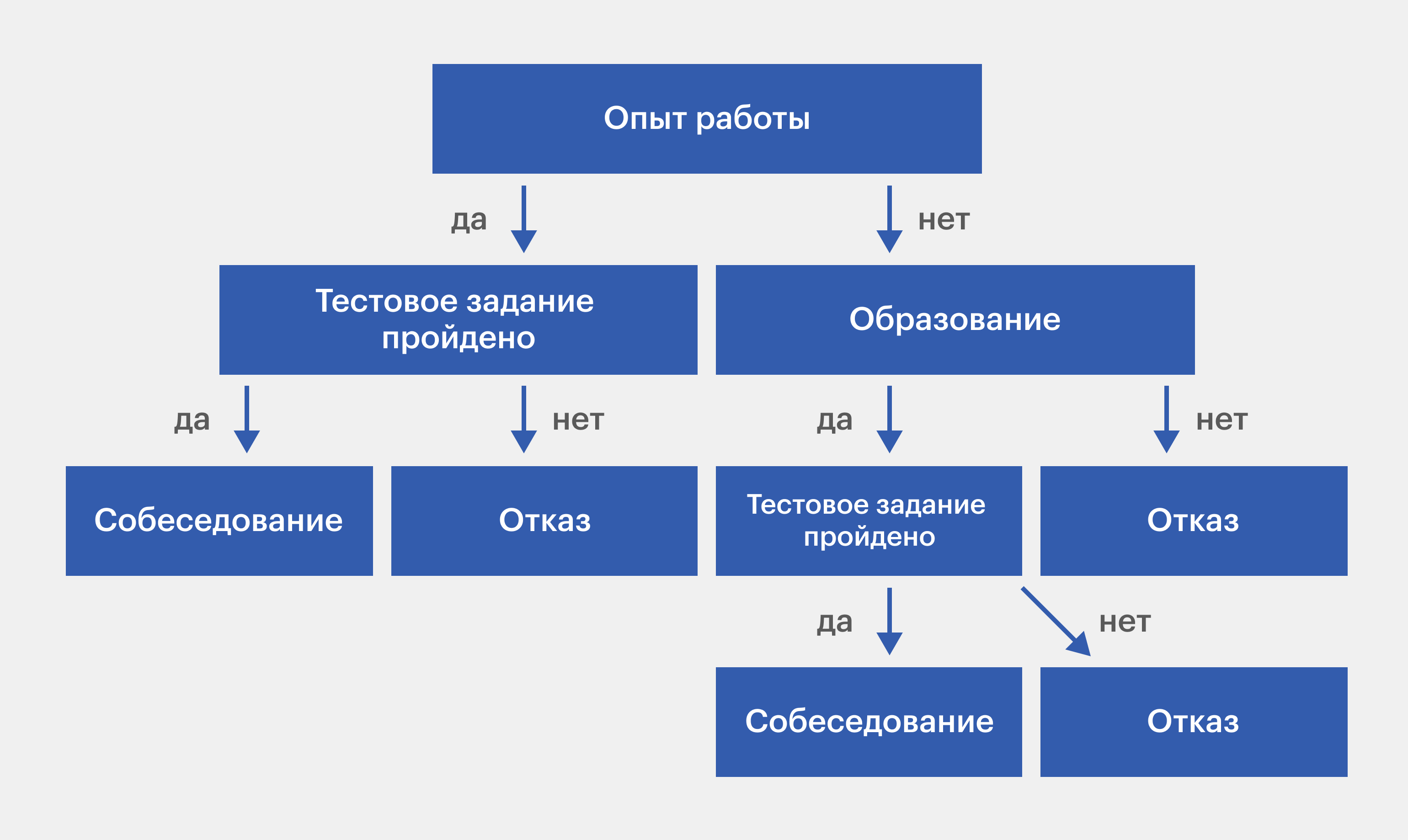
Определение взаимосвязей между признаками
Одним из ключевых этапов при построении дерева решений является определение взаимосвязей между признаками. Как правило, внешне на первый взгляд независимые переменные на самом деле могут иметь скрытую корреляцию, которая может оказывать значительное влияние на целевую переменную.
Для выявления этих взаимосвязей можно использовать различные статистические методы и анализ данных. Например, можно построить матрицу корреляций или использовать метод главных компонент для выделения основных факторов, влияющих на целевую переменную.
Определение взаимосвязей между признаками позволяет более точно оценить важность каждого признака для прогнозирования целевой переменной. Если два признака сильно коррелируют друг с другом, то один из них может быть исключен из модели или использоваться только один из них для предсказания целевой переменной. Это позволяет сделать модель более интерпретируемой и снизить риск переобучения.
Кроме того, определение взаимосвязей между признаками может помочь выявить скрытые закономерности и зависимости в данных, которые могут быть использованы для улучшения качества модели. Например, если два признака имеют слабую корреляцию самостоятельно, но при их комбинировании они сильно влияют на целевую переменную, то можно создать новый признак, объединяющий эти два, и использовать его в модели.
Определение взаимосвязей между признаками также позволяет провести более глубокий анализ данных и понять, какие признаки на самом деле важны для решения анализируемой проблемы. Иногда бывает, что некоторые признаки несут только лишнюю информацию и не влияют на целевую переменную, поэтому их можно исключить из модели.
Определение взаимосвязей между признаками является важным шагом при построении дерева решений, так как позволяет создать более точную и эффективную модель, а также провести более глубокий анализ данных и понимание анализируемой проблемы.
Выбор наиболее эффективной модели
Выбор наиболее эффективной модели является важным этапом в построении дерева решений. Качество модели напрямую влияет на точность прогнозирования результатов и эффективность в решении анализируемой проблемы.
1. Оценка производительности моделей
Для выбора наиболее эффективной модели необходимо оценить и сравнить их производительность. Это можно сделать путем использования метрик оценки, таких как точность, полнота, F-мера, площадь под ROC-кривой и другие. Также можно провести кросс-валидацию, чтобы получить более надежные оценки производительности для каждой модели.
2. Учет особенностей проблемы
При выборе модели необходимо учитывать особенности анализируемой проблемы. Некоторые модели могут быть более подходящими для определенных типов данных или задач, например, линейная регрессия для задачи предсказания непрерывной переменной, или случайный лес для задачи классификации с большим количеством признаков.
3. Регуляризация и подбор гиперпараметров
Важным моментом при выборе модели является регуляризация и подбор гиперпараметров. Регуляризация позволяет уменьшить переобучение модели и повысить ее обобщающую способность. Подбор гиперпараметров позволяет настроить модель под конкретную задачу и данных, улучшая ее производительность.
Выбор наиболее эффективной модели в построении дерева решений играет ключевую роль в достижении высокой точности прогнозирования и решения анализируемой проблемы. Оценка производительности моделей, учет особенностей проблемы, регуляризация и подбор гиперпараметров являются важными шагами при выборе наиболее подходящей модели.



